背景
相信很多人学生时代都有过这样的经历:没有老师的自习课,教室里像集市一样吵闹;可一旦听到走廊里传来熟悉的脚步声,又能瞬间变得鸦雀无声。
但更有趣的是,有时候根本不需要老师现身,同学们也能在极其短暂的时间内,不约而同地安静下来。明明没有人喊"老师来了",明明没有任何明显的警告,可全班就像是商量好了一样,突然就没人说话了。这种"自发静默"的现象,确实耐人寻味。
群体默契与心理暗示
人是社会性的动物,很容易受周围环境的影响。当一个人率先安静下来,其他人也会不自觉地效仿,最终形成某种"无声的默契"。
此外,心理暗示的作用同样不可忽视——一句"老师来了",一个示意安静的手势,足以让所有人瞬间进入"课堂模式",仿佛条件反射般自觉安静下来。
复杂系统理论
我们不妨把课堂看作一个复杂适应系统,学生就是系统中的个体,彼此互动,共同营造课堂氛围。当老师出现,或者有学生率先闭上嘴巴,其他学生也会随之行动——这既是"从众心理"的体现,也是复杂适应系统中"涌现"现象的体现。课堂氛围的变化,也是系统对内外环境变化的自适应。
那么,什么是复杂适应系统?简单来说,就是由众多相互作用、不断适应的个体所组成的系统。在这个系统中,个体之间并非孤立存在,而是通过种种联系紧密相连,共同构成一个有机整体。个体在与环境及其他个体互动的过程中,不断学习、进化,从而使整个系统呈现出动态平衡和自组织的特性。
什么是"涌现"?就是系统整体所表现出的性质,并非个体性质的简单叠加,而是由个体之间相互作用所产生的新性质。比如蚁群的智慧,并非单个蚂蚁所具备,而是由无数蚂蚁协同合作所产生的。
建模思路
自习课上高谈阔论,这种行为多少有点"违规"。从小接受的规则意识教育,使我们在违反纪律时产生一种微妙的负罪感,于是在精神上处于一种高度警觉的状态。
心理学上认为,老师在学生心中具有权威形象,代表着规则和秩序。老师一旦现身,学生潜意识里就会自觉遵守纪律,肃然安静。这就是条件反射——就像巴甫洛夫的狗听到铃声会流口水一样。
学生的精神处于高度警觉状态,各种感官都被调动起来,随时关注教室外每一个"危险"信号。动物行为学家把这种高度紧张的状态,及表现出应对未知危险的行为趋势称为"冻结反应"(The Freeze Response)。
如果有人误以为从窗户反光中看到了老师的身影,多会选择噤声自保。随着发声的人减少,环境音量因之降低,反而更能引起其他人的警觉,使其纷纷效仿。在这个正反馈效应中,教室内音量降低的速度越来越快。原本喧闹的教室,在看似没有任何警报的情况下,在极短时间内变得鸦雀无声。
方法与结果
一维元胞自动机
我们用一维元胞自动机来模拟这个过程。元胞自动机是由一列元胞构成的,每个元胞有自己的状态,按照规则在下一个时间步更新状态。
在这个模型中,我们模拟的是一个五十人课堂的场景,每个元胞代表一名学生。每个学生可以处于"说"或"听"两种状态。我们用一列元胞来模拟课堂中学生们的状态,给每个元胞赋一个数值,正数表示"说",负数表示"听"。
假设时间步长为每0.1秒,学生说一句话最长需要10秒。我们给每个元胞随机赋值为-100到+100之间的整数。每个时间步,让状态数值的绝对值减1。如果元胞初始值为+100,经过100个时间步后减到0,表示一句话说完,需要10秒。当数值归零,下一个时间步就重新随机赋值于-100到+100之间。这样就能模拟出课堂中人声鼎沸的情形。
我们用18000个时间步来模拟三十分钟内五十名学生在自习课上的聊天情形。
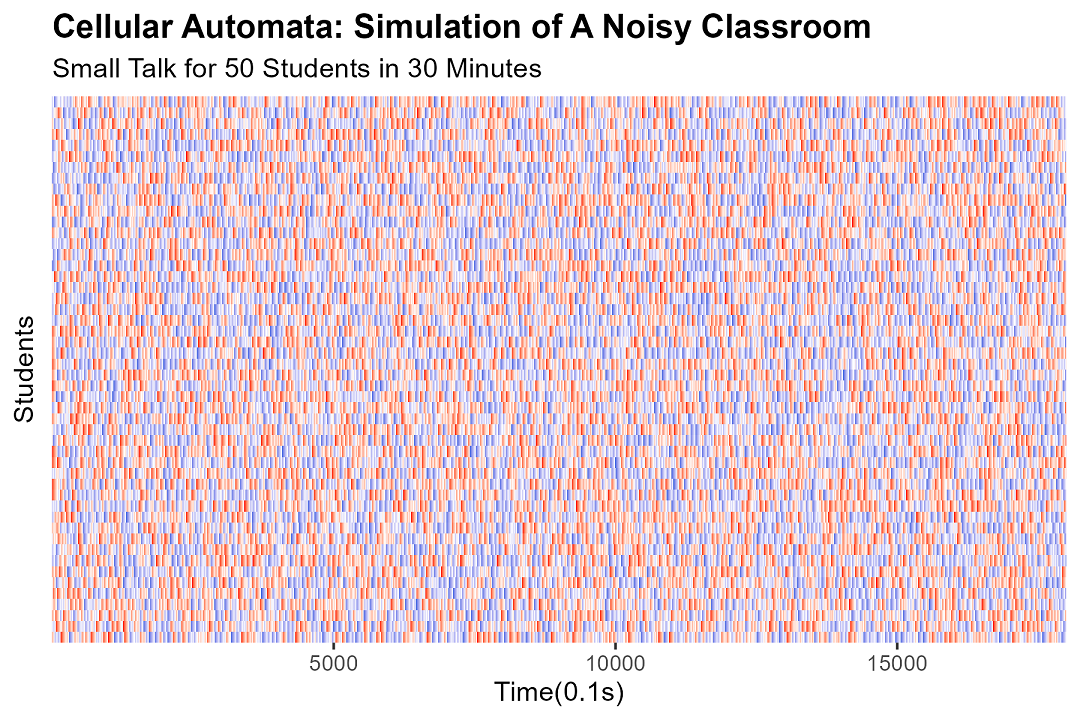
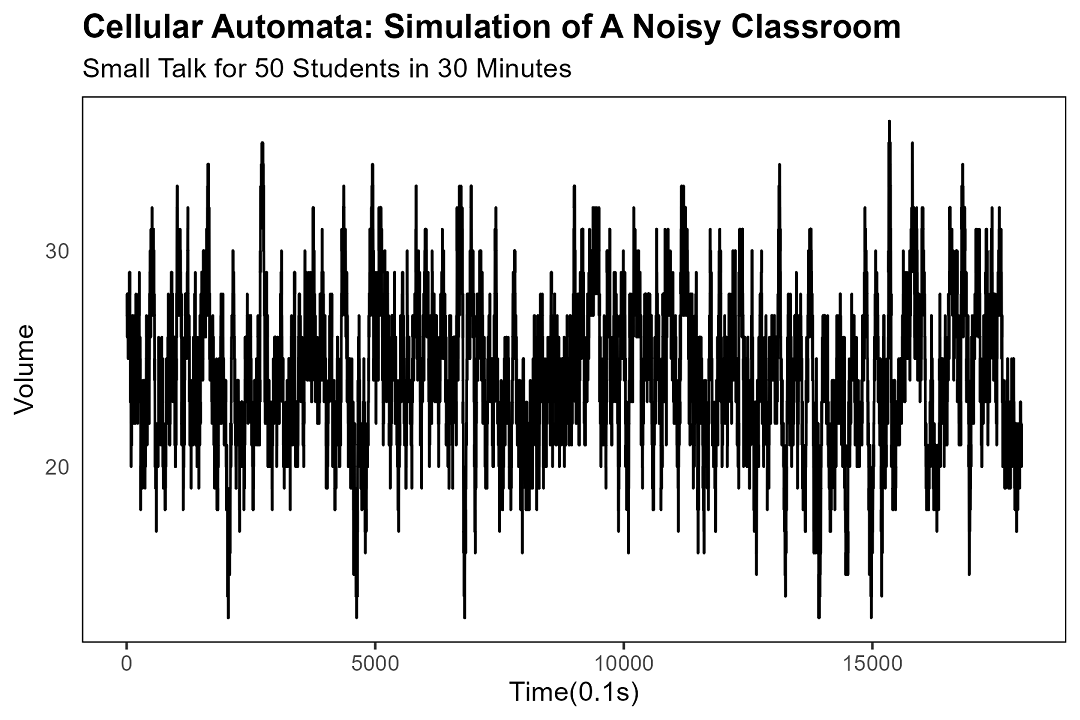
通过统计当前时刻课堂中发言学生的人数,来衡量当时的噪音音量。
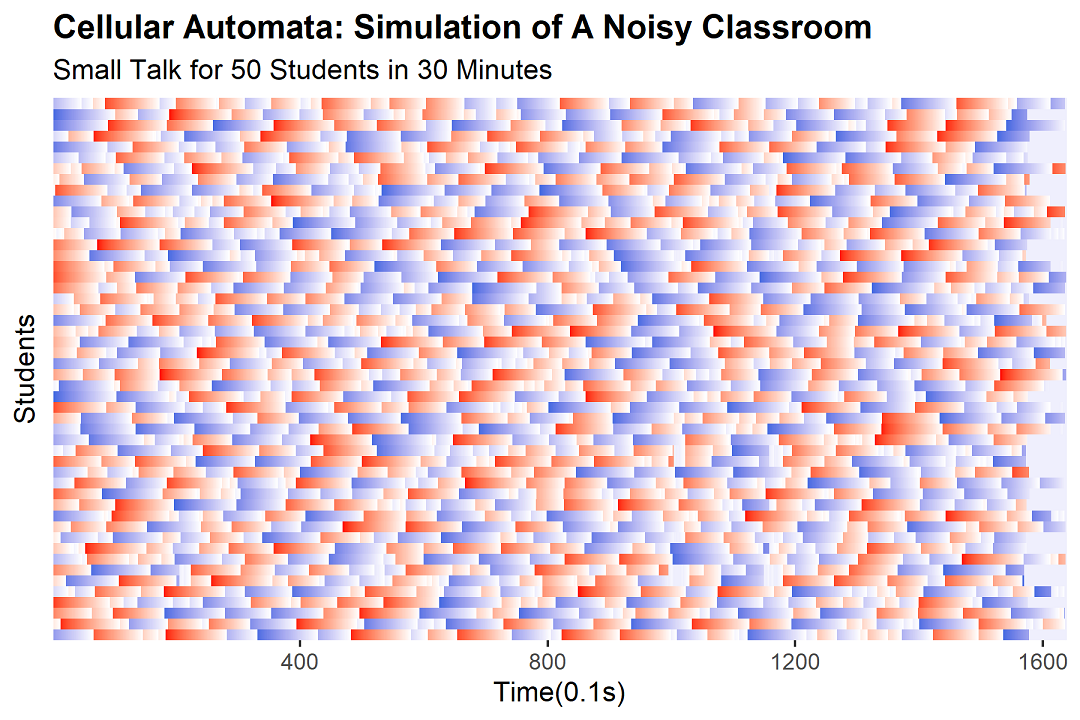
冻结反应
现在,我们把学生对老师的"心理阴影面积"和"冻结反应"考虑进来。为每个学生增设一个对低音量的警觉性x(注意,每个人对噪音的敏感程度不同,所以警觉性也有所差异)。
例如,对于学生甲来说,如果课堂内说话的人数少于x人,他就会进入警戒状态,停止说话一秒。有些学生"心理阴影面积"比较大,更容易把音量下降误认为是老师出现带来的"压迫感",所以x值相对较高;而胆大的学生,则需要等到课堂中只剩他一个人在跟同桌说话时才能意识到,x值就比较小。我们把这个x称为"心理阴影面积最小冻结音量",简称"最小心冻音量"。
在现有的一维元胞自动机基础上,我们需要添加新规则:在更新每个学生(元胞)状态数值时,先观察上一个时间步(即前0.1秒)的噪音音量是否低于该学生的最小心冻音量(即该元胞的x)。如果是,则在下一个时间步将状态数字重置为-10,表示接下来一秒内(十个时间步)该学生将采取"停、看、听"的策略;如果否,则按原规则继续填入数值。
每次重置,都有可能使课堂噪音下降,逐渐逼近另一位学生的最小心冻音量x,促使更多人产生冻结反应。这就是"自发静默"现象的成因。
在这次模拟中,三十分钟内五十名学生在自习课上的聊天情形,引入最小心冻音量后,在约160秒左右,出现了自发静默的现象。
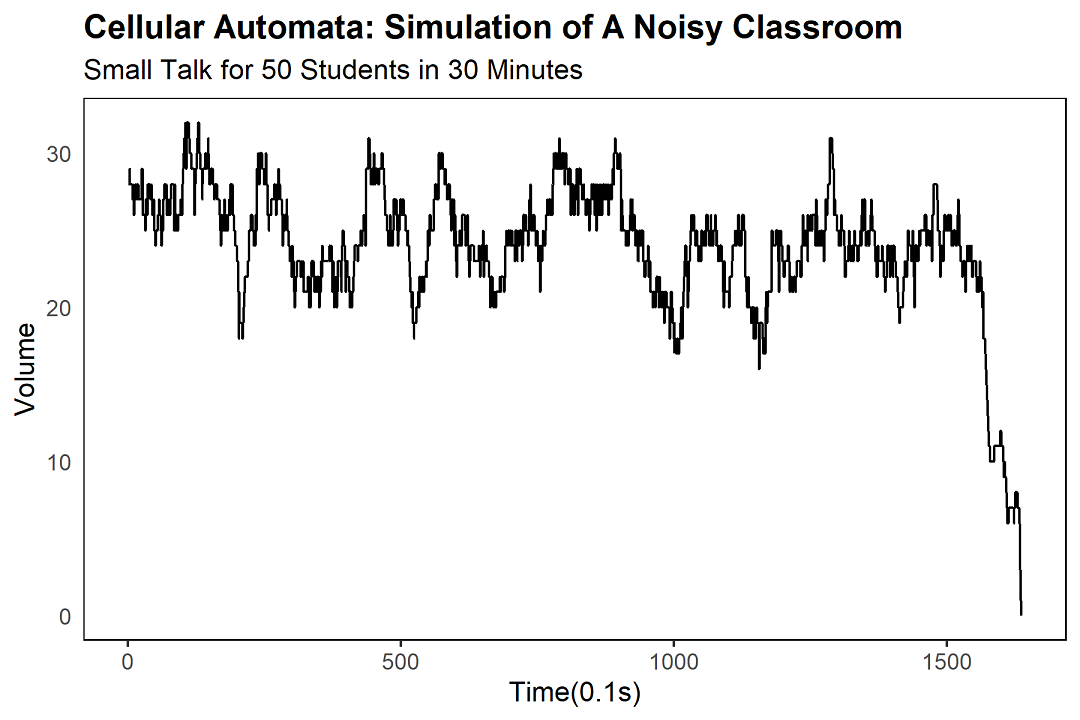
群体默契发生与否,与系统规模存在复杂关联,非线性复杂系统对初始参数非常敏感,所以模型的参数化过程需要谨慎。通过元胞自动机模拟所得数据,我们可以探究学生"最小心冻音量"对"自发静默现象"的主效应。
在这个模型中,每个元胞的初始状态是随机的,只需要对每个学生的最小心冻音量进行参数化设定。
为了让模拟更契合实际情形,我们设置了对老师出现不太敏感的学生,其最小心冻音量的最小值设为3(x_min = 3),即当课堂中仅剩3名学生说话时,该学生方才进入"冻结"状态。至于最小心冻音量的最大值,因难以依据现实情境确定,需通过模拟试验来探求。需要注意的是,如果无法对模型进行适当的参数化,则难以在有限(可计算之)时间步内观察到自组织现象的发生。
在x_min = 3,且x_max = 17的参数下,我们进行了一万次模拟,并记录每次模拟中所有学生最小心冻音量之和S_x = Σ_i^50 x_i,与自发静默现象发生时间T(模拟时间步最大为18000,即三十分钟)的关系。
| Estimate | Std.Error | t | P | Sig. | |
|---|---|---|---|---|---|
| 6.0676688 | 0.0829139 | 73.18 | <2e-16 | *** | |
| $S_x$ | -0.0056127 | 0.0001652 | -33.97 | <2e-16 | *** |
表1:自发静默之现象发生时间与学子"心理阴影面积"之总和的线性回归
我们将x_max的最大值设为15到19,分别进行了上千次模拟。随着x_max增加,自发静默现象的时间提前。统计这组实验中三十分钟内出现沉默现象的次数,计算频率。通过逻辑斯蒂回归获得拟合方程:
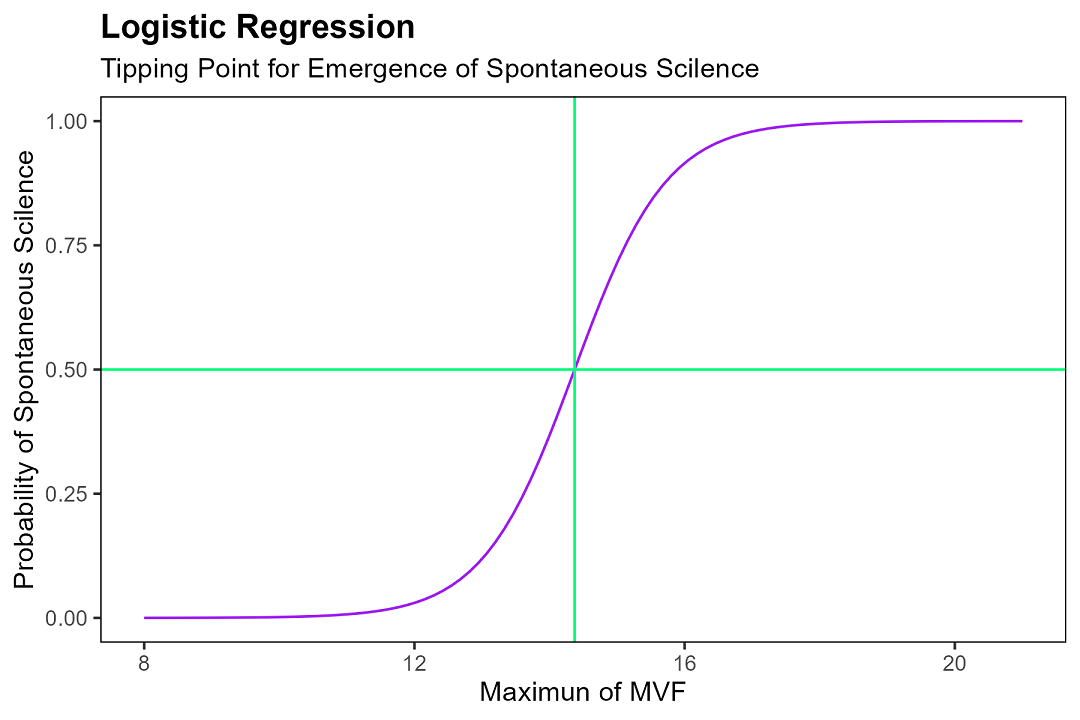
图6:逻辑斯蒂回归模型 y=[1+exp(-1.463x+21.019)]^{-1} 及阈值
上述模型可以这样理解:自习课堂上,当同时说话的学生人数降到一定数目以下时,将引发连锁的"冻结反应",可能导致课堂在极短时间内趋于寂静。在三十分钟的自习课中,如果五十名学生中最小心冻音量(心理阴影面积的替代变量)的最大值超过临界点14(tipping point),则自发静默现象发生的可能性大为增加;如果最大值超过19,则在三十分钟内至少出现一次沉默现象的概率极高。
结语
“冻结、逃跑、战斗”(Freeze, Flight, Fight)三者,似乎已成为动物和人类面对危险时普遍的行为趋向。科学研究表明,停止活动作为一种本能反应,对被捕食的猎物而言,可能是最合理的选择。这是因为食肉哺乳动物的视觉皮质与视网膜,在进化过程中,对动态物体的察觉愈加敏锐。所以猎物若能善用"停、看、听"以自保,便更有可能逃脱天敌的追捕。在自然选择之下,我们的大脑边缘系统学会评估周围环境的危险等级,这种预警机制的形成与保留,确实有助于我们的生存和繁衍。
在国外,有一个短语专门用来描述这种突然安静的现象,叫作"天使飞过"(Angel passing by)。
也许有一些老师真的是我们生命中的天使。直到长大成人,我才渐渐感受到教师这个职业的伟大。当我们发现靠自律来养成好习惯,不是一件容易的事情,才知道曾经的那些严格要求,帮我们在残酷的升学制度的竞争中克服了拖延和懒惰。
回首人生最初的十几个春秋,有一些人仅仅在你生命长河里出现一两年,甚至更短的时间,却真心地为你着想。越长大,身边这样的人就越少了。希望大家能对那些让你学会"闭嘴保平安"的"天使"们说一声谢谢。
即便如此,自习课上还是少不了几个"牺牲品",来帮助老师杀鸡儆猴。玩归玩,闹归闹,别拿老师开玩笑。
附录一:元胞自动机实现
i <- 1
timestep <- 1
timeout <- 18000
students <- 50
t0 = round(runif(students, -100, 100))
ca <- cbind.data.frame(t0)
volume <- vector(mode="numeric")
volume[timestep] <- sum(ca[,timestep] > 0)
mentalshadow <- round(runif(students, 3, 19))
while(volume[timestep] != 0){
for(i in 1:students){
if(volume[timestep] < mentalshadow[i]){
ca[i, timestep + 1] <- -10
}
else {
if(ca[i, timestep] == 0) {
ca[i, timestep + 1] <- sample(-100:100, 1)
}
else if(ca[i, timestep] > 0) {
ca[i, timestep + 1] <- ca[i, timestep] - 1
}
else {ca[i, timestep + 1] <- ca[i, timestep] + 1}
}
}
colnames(ca)[timestep+1] <- paste0("t", timestep)
timestep <- timestep + 1
if(timestep == timeout){volume[timestep] = 0}
else{volume[timestep] <- sum(ca[, timestep] > 0)}
}
附录二:向量计算的陷阱
在 R 语言中,向量计算往往因其高效性而被广泛采用,向量化操作比 for 循环更快,这是因为 R 的底层计算基于 C 语言优化,使得整个向量可以一次性传递给计算函数,而无需逐个元素进行解释和处理。
在根据规则来生成模拟数据时,通常优先考虑向量计算(ifelse),而非循环遍历。然而,在涉及随机赋值的情境下,如果不加注意,向量计算可能会意外地引入“锁步”的陷阱,引入模式化的行为,破坏了模拟的随机性和异质性。
同步演变下的异常模式
如本文的模拟场景,每个个体的状态数值可以在一定范围内波动,遵循以下规则:
- 若状态为正数,则逐步减少;若状态为负数,则逐步增加。
- 若状态为 0,则该个体会被赋予一个新的随机值。
ifelse(state == 0, sample(new_values, 1), state ± 1)
这个过程应该保持较高的个体异质性。当我们使用向量计算直接实现时,个体状态是同步变化。
set.seed(1)
ca <- data.frame('step0' = round(runif(50, min = -100, max = +100)))
for (t in 1:100) {
ca_rule <- ifelse(ca[, t] == 0, sample(-100:100, 1),
ifelse(ca[, t] > 0, ca[, t] - 1, ca[, t] + 1))
ca[,ncol(ca) + 1] <- ca_rule
colnames(ca)[ncol(ca)] <- paste0("step", t)
}
rownames(ca) <- paste0("Student ", 1:50)
表面上看,这段代码完美执行了我们想要的规则。然而,这里的问题在于 sample(-100:100, 1) 仅生成一个随机数,然后将这个单一数值赋给所有状态为 0 的个体。
如果某个时间步内有多个个体同时满足 state == 0 的条件,它们将在该时间步获得完全相同的值,并在接下来的演化中保持相同的变化趋势。
pheatmap(ca,
cluster_rows = TRUE,
cluster_cols = FALSE,
show_rownames = TRUE,
show_colnames = FALSE,
treeheight_row = 0)
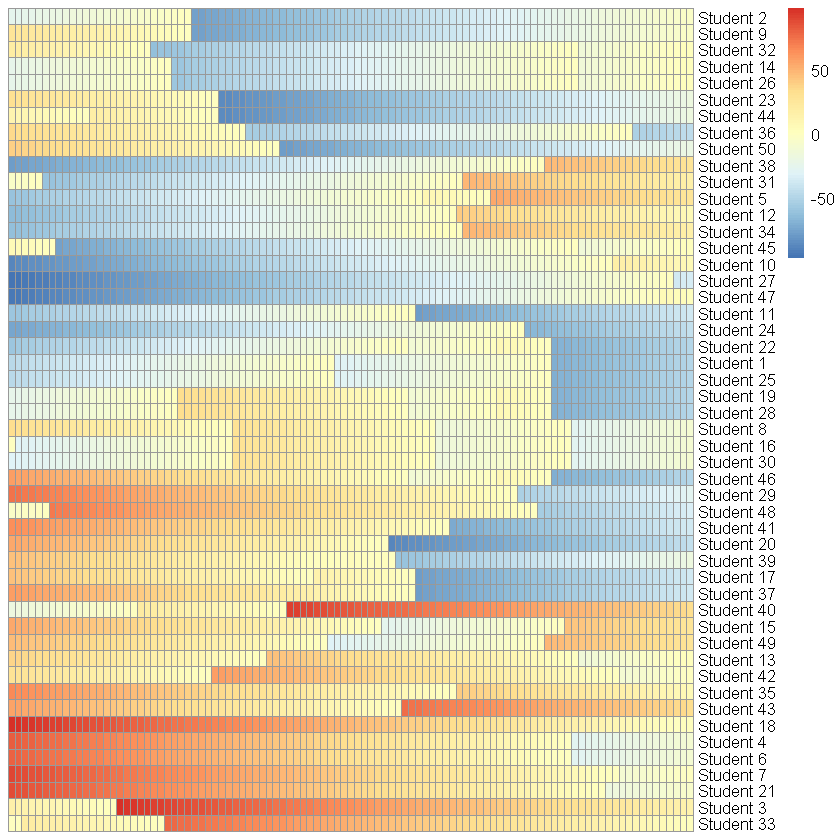
这种模式的典型特征是:
- 如上图,某些个体状态的演化轨迹变得完全相同,形成“锁步”。
- 预期的个体异质性被破坏,可能导致整个模拟结果失真。
- 若同步个体的比例较大,模拟结果可能与预期目标产生较大偏差。
这种现象削弱了模拟的随机性,影响个体层面的异质性,甚至改变原本预期的模拟行为。
如何避免?
要保持个体间的独立性,我们需要确保每个个体的状态更新过程真正独立,特别是在随机赋值时。最直接的方法是为每个需要重新赋值的个体单独生成随机数,而不是使用一个统一的随机值。
一种方法是先找到所有满足 state == 0 的个体索引,然后逐个赋予不同的随机值。这一方式可以避免同步陷阱,同时仍然保持向量计算的高效性。
vectorized_update <- function() {
ca <- data.frame('step0' = round(runif(50, min = -100, max = +100)))
for (t in 1:1000) {
zero_indices <- which(ca[, t] == 0)
new_random_values <- sample(-100:100, length(zero_indices), replace = TRUE)
ca_rule <- ifelse(ca[, t] == 0, NA,
ifelse(ca[, t] > 0, ca[, t] - 1, ca[, t] + 1))
if (length(zero_indices) > 0) {
ca_rule[zero_indices] <- new_random_values
}
ca[, ncol(ca) + 1] <- ca_rule
colnames(ca)[ncol(ca)] <- paste0("step", t)
}
}
与之相比,传统的循环遍历方式可以逐个为每个个体生成随机数,从而保证了个体更新的独立性,避免了“锁步”模式的出现,但这种方法往往牺牲了运行效率。
loop_update <- function() {
ca <- data.frame('step0' = round(runif(50, min = -100, max = +100)))
for (t in 1:1000) {
ca_rule <- numeric(50)
for (i in 1:50) {
if (ca[i, t] == 0) {
ca_rule[i] <- sample(-100:100, 1)
} else if (ca[i, t] > 0) {
ca_rule[i] <- ca[i, t] - 1
} else {
ca_rule[i] <- ca[i, t] + 1
}
}
ca[, ncol(ca) + 1] <- ca_rule
colnames(ca)[ncol(ca)] <- paste0("step", t)
}
}
ifelse()向量化操作的底层用 C 语言实现,比for逐个遍历快很多。- 同时,因为
sample()在vectorized_update()中一次性生成多个随机数,而loop_update()逐个生成,调用次数远多于向量化方案。 - 此外,
which(ca[, t] == 0)一次性找到所有state == 0,也比循环判断更高效。
预期向量化方案将比循环遍历快得多,尤其当 t 变大时,累积性能差距更明显。
replicate(5, system.time(vectorized_update())["elapsed"])
0.340000000000146
0.319999999999709
0.340000000000146
0.270000000000437
0.25
replicate(5, system.time(loop_update())["elapsed"])
2.5
2.42000000000189
2.40999999999985
2.90000000000146
2.88999999999942
通过 system.time() 测量后,我们可以发现向量化方法在大规模数据下通常能显著缩短运行时间,而循环遍历的开销较大。
综上,尽管向量化计算在性能上具有无可争议的优势,尤其在大规模数据或长时间步模拟中能够显著缩短运行时间,但在处理随机化操作时必须格外谨慎。
对比之下,采用自下而上、逐个遍历的方式(即使用 for 循环逐个处理每个元素)虽然在性能上有所牺牲,却能确保每个元素获得独立的随机数,从而保留向量中各个元素的独立性,进而提升模拟结果的科学性和可靠性。